Following the recent publication of his latest study in The Journal of Experimental Political Science, Dr Thomas J. Leeper discusses his research into convenience samples and considers whether such analysis should really be trusted in political science.
One of the first lessons of any statistics course is that the only way to obtain a valid inference about a population – short of interviewing every single individual – is to base that inference on a randomly selected sample of individuals. Research on political behaviour is therefore frequently seen as requiring population-representative samples in order to make useful claims about how citizens think, reason, and act with regard to politics. Despite these assumptions, a large amount of political behaviour experiments are instead conducted with “convenience samples” – individuals who are willing to participate in studies but are not randomly sampled.
The results of our study challenge many of the long-standing concerns about experimental research in political science. The team, including myself, Dr Kevin Mullinix from Appalachian State University, Prof James N. Druckman from Northwestern University, and Prof Jeremy Freese now of Stanford University, conducted a large scale replication of over twenty political science experiments using both nationally representative online samples of respondents and frequently used convenience samples, including the widely used Amazon Mechanical Turk crowdsourcing platform.
The project really began in 2012. My co-authors and I noticed that many researchers were willing to quickly disregard research that used convenience samples. When presenting research using convenience samples, we would frequently hear audience members say ‘these aren’t real people’. This is something political behaviour researchers are used to hearing and, in fact, we had started seeing a lot of papers comparing the demographics of convenience samples to national samples and – unsurprisingly – finding differences. But we thought those comparisons were asking the wrong question.
We thought instead that the measure of any convenience sample is whether it generates experimental results that are indistinguishable from those that would have been found with a population-representative sample. In other words, we decided that instead of focusing on whether convenience samples looked like national samples (a form of “face validity“) the more important question was whether the results of a study relying on a convenience sample would have differed had it instead been conducted with a national sample.
The research proceeded in two parts. First, our team began by conducting a set of “framing” experiments, in which we manipulated the information respondents received about each of three policies, and measured respondents’ support for each. Unlike past research, however, we implemented these studies not with just one sample but rather simultaneously with a nationally representative sample and four of the most commonly used convenience samples in political science research: namely samples of university undergraduates, university staff, a post-election exit poll, and Amazon Mechanical Turk. Examining the effect size in each study, we found striking similarities rather than differences. The experiments yielded nearly identical results from each sample despite substantial differences in sample characteristics.
Not satisfied with these results, we developed a second study focused more in-depth on the comparison between the increasingly popular Amazon Mechanical Turk platform and a national sample. We broadened our focus by starting from a set of 20 nationally representative survey experiments funded by Time Sharing Experiments for the Social Sciences, a United States National Science Foundation funded program for which Profs Druckman and Freese are PIs and I am an Associate PI. We replicated these experiments using respondents recruited from Amazon Mechanical Turk. This significantly broadened the types of experiments being compared to test whether the similarities found in the first study were credible. Yet again, we found similarities. Where the national sample had found large effects, so too did the convenience sample; where the national sample found no effect, so too did the convenience sample (see Figure below). The effects in the national and convenience samples were statistically indistinguishable in 16 out of 20 experiments.
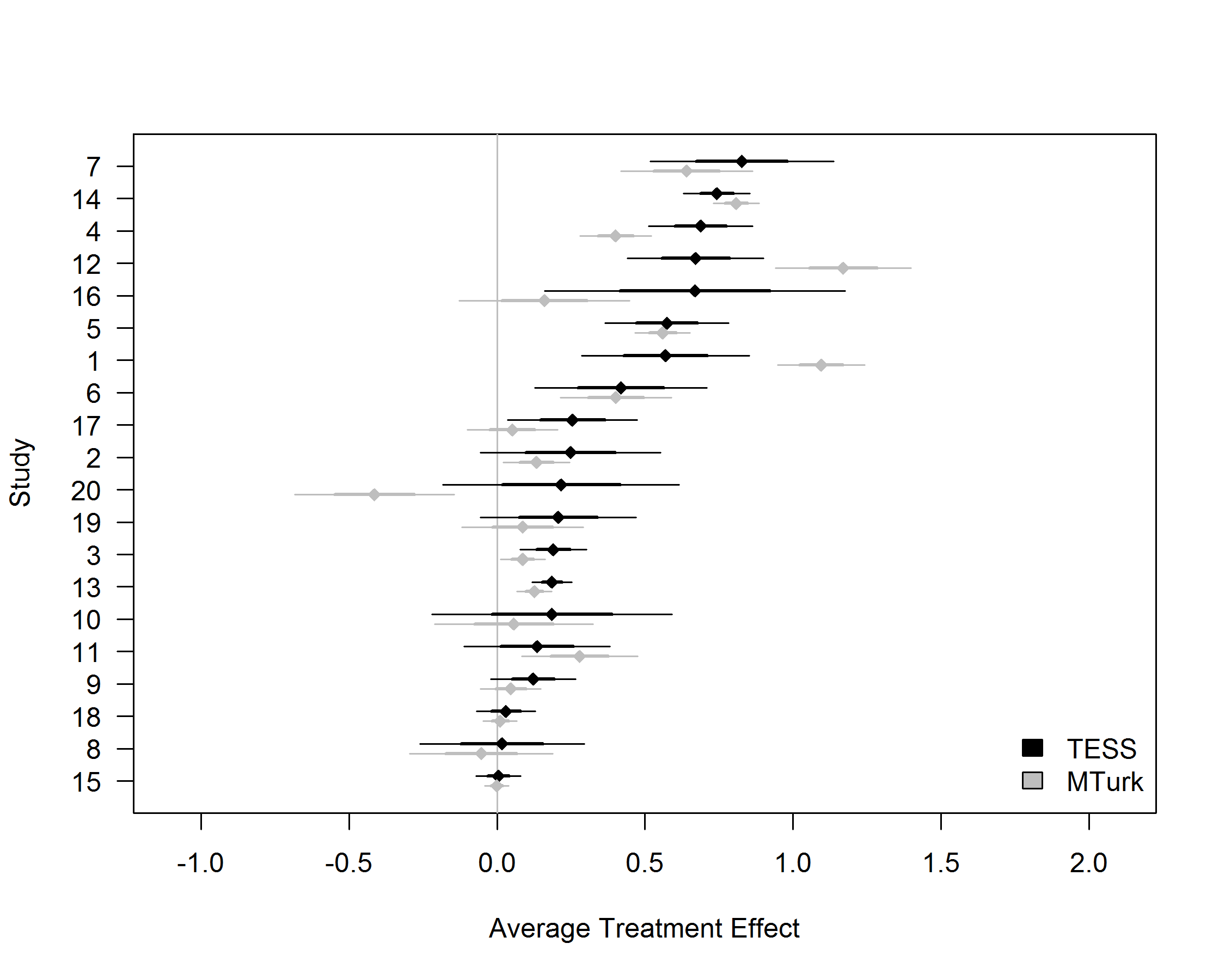
The research speaks well to an ongoing discussion about the replicability of experimental results in fields including political science and psychology. These results show that convenience samples play a valuable role in political science research. As we write in the paper: “scientific knowledge advances through replication rather than accepting or rejecting research based on sample-related heuristics.”
Similarity of findings across so many replications also stands out in contrast to recent findings from a large-scale replication project that was published in Science last August. That study found that less than half of studies published in three top-ranked psychology journals were able to be replicated by other teams implementing the same research designs. Some have read that evidence as a bad sign for contemporary social science.
The new study by me and my collaborators suggests that more work is needed before we give up hope. Finding that most replications produced similar results even in vastly different samples means there is reason to be more confident about published experimental findings than the “replication crisis” would have you believe.
 Dr Leeper is an Assistant Professor in Political Behaviour in the Department of Government at the LSE. You can read Dr Leeper’s research paper in the Journal of Experimental Political Science. You can visit Dr Leeper’s personal website and follow him on twitter. This piece does not give the view of the Department of Government, nor the London School of Economics.
Dr Leeper is an Assistant Professor in Political Behaviour in the Department of Government at the LSE. You can read Dr Leeper’s research paper in the Journal of Experimental Political Science. You can visit Dr Leeper’s personal website and follow him on twitter. This piece does not give the view of the Department of Government, nor the London School of Economics.



