James Sanders

Argumentative characteristics of the official Brexit campaigns
On 23 June 2016, the Brexit Remain campaigners failed to persuade sufficient voters to remain in the EU. Accusations have been made that their message (often dubbed “Project Fear” and described as “remoaners”) projected a more negative image to the electorate than the Leave campaign. What is the evidence for this? Did the Remain campaign systematically project a more negative image to the electorate than Leave and to what extent did the campaigns significantly focus on different policy issues? I aim to answer these questions, and more, in the setting of the official Brexit campaign websites.
Designated by the Electoral Commission on the 13th April 2016, ‘Vote Leave’ and ‘Britain Stronger in Europe’ became the official campaigns for Leave and Remain respectively. I will study the variation in linguistic characteristics across these two campaigns by breaking the argumentative text into two components: (1) what information is being presented (focus); and (2) in what style is this information presented (sentiment). I will then analyse the focus and sentiment independently.
Focus:
Having scraped both campaign official websites, I attempt to analyse variation in focus between Leave and Remain using a statistical method called a “structural topic model” (STM) (explained in the Appendix1). Those clusters to the left of the dotted line were more associated with Remain, and those to the right were more strongly associated with Leave.
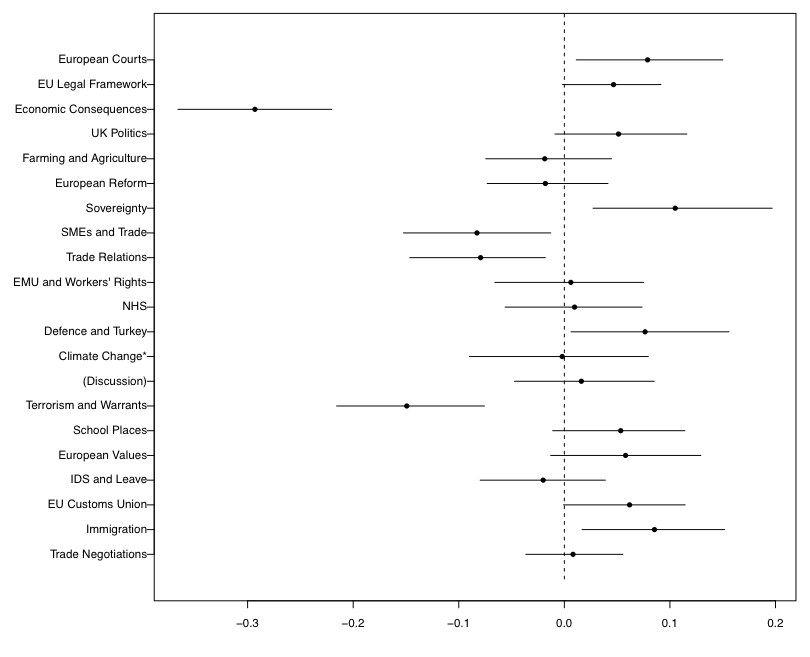
Figure 1
Figure 1 shows the stark differences in focus between the two official campaigns. Britain Stronger in Europe focussed disproportionately on topics related to the macroeconomy, international trade and businesses, demonstrated via their associations with the topics “Economic Consequences”, “Trade Relations”, and “SMEs and Trade”. The only non-economic topic disproportionately related to Remain was “Terrorism and Warrants”. On the other hand, Vote Leave spread their focus across a broader array of policy areas. These included: “European Courts”, “Sovereignty”, “Defence and Turkey” and “Immigration”. Although generally a set of broad and disparate topics, it could be argued that these are underpinned with the targeting of British sovereignty.
To test the robustness of my results, I conduct a thematic analysis of elementary contexts using a proprietary software called T-LAB. I find a re-emergence of the economic-sovereignty divide between the two campaigns. My results also confirm Remain’s “focussed” approach of dedicating disproportionate resources to a small number of economic topics, and Leave’s “scattershot” approach of spreading their resources over a broader set of policies. This analysis uncovers little reciprocity across topics, that is, both campaigns focussed on their “home” topics, rather than addressing the arguments of the opposing campaign. This held for all but one topic, “Public Services and NHS”, which was equally spatially associated to both camp tags.
In the months leading up to the referendum, YouGov surveyed the British public on their preferences regarding a range of referendum-related subjects. These subjects included their opinions of British politicians, their voting intentions in the upcoming referendum, and the perceived consequences of leaving the EU. The same questions were surveyed roughly fortnightly from February until 22nd June (the day before polling). By using the topics I identified previously, I can use survey responses as a signal for the potential effectiveness of each camp’s approach.
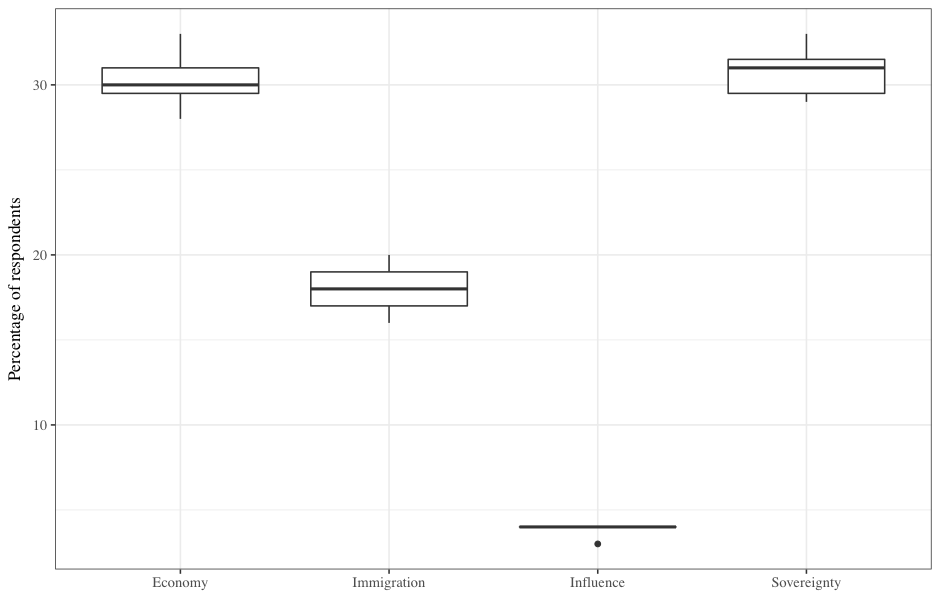
Figure 2
Figure 2 shows the percentage of respondents who gave certain responses to the question “Which ONE of the following will be most important to you in deciding how to vote in the referendum?”. If we compare campaign focus to these survey results, although Remain focussed on an extremely influential topic for the electorate, Leave’s scattershot approach managed to capture a larger proportion of the total electorate. Importantly, this quick analysis does forgo how convincing arguments are, nonetheless it is an interesting analysis of campaigning intention.
Sentiment:
The second characteristic of argumentative text is the way chosen information is conveyed to its audience. This can be done through webpage design, sentence structure, and other literary techniques. One such method is the use of sentiment. In this context, sentiment analysis is the process by which a researcher aims to establish how positive or negative a segment of text is. For example, “this food is bad” may be interpreted as negative, “this food is great” as positive, and “this food is okay” as neutral.2
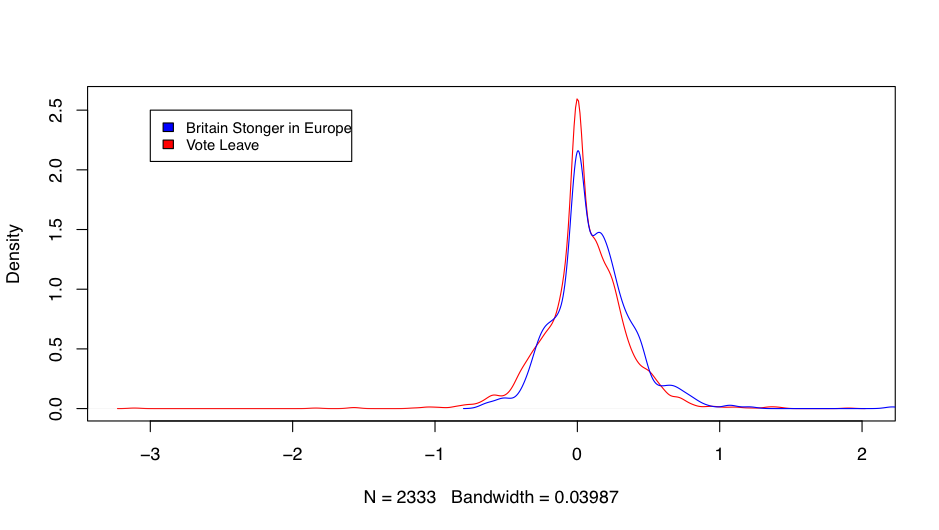
Figure 3
Figure 33 provides a visual representation of the distribution of sentence sentiment within each campaign, with rightward being more positive and leftward more negative. We observe an almost normal-looking distribution with a slight rightward skew for both campaigns. Statistically, we find that the sentiment used by Britain Stronger in Europe was significantly more positive than Vote Leave.4
Conclusions:
Overall, an analysis of focus and sentiment uncovered two very different campaigns. The first, Britain Stronger in Europe, conducted a focussed approach which emphasised the economic arguments for staying a member of the European Union. This campaign was also significantly more positive than its Leave counterpart. Vote Leave engaged a scattershot approach which spread their resources across a broader range of policy issues. This allowed them to capitalise on a larger subset of the electorate. Neither campaign was particularly responsive to the argumentation of their opposing number, with a notable exception being Public Services and NHS, which acted as a key battleground.
Editor’s note:
This blog was written and contributed by LSE BSc Government and Economics student James Sanders in preparation for the presentation of his paper at the 2017 UPR Conference. For more information on the upcoming Conference see here.
Appendix
1 Based off more traditional topic models, the STM divides the text into distinct clusters with similar characteristics. Its innovation, however, is that it permits the inclusion of document-level metadata (or “tags”), allowing the researcher to study the relationship between these covariates and topics. Substantively, I can see which topics were more strongly associated with remain than leave, and vice versa, in a “difference estimation”. Figure 1 is the difference estimation with 90% confidence intervals.
2 To study variation in sentiment between the official campaigns, I use the “sentimentr” package to calculate a sentence-level score as a single observation. Repeating this for all sentences in both websites, we can study the distribution of sentence-level scores.
3 Figure 3 is the kernel density estimation for both distributions of polarity scores.
4 Using these two distributions we can test for similarity in mean (0.04914 for VL and 0.10754 for BSE) and variance. Using a generalised linear model with Gaussian errors, we find that Britain Stronger in Europe was significantly more positive than Vote Leave (t = 4.359, P = 1.351 × 10−5 * * *). This result is confirmed if we drop all parametric assumptions and use a Kruskal-Wallis test. Finally, a Levene’s test uncovers no significant difference in the variability of both distributions.