This post is based on a presentation I gave at this afternoon’s M25 Learning Technology Group meeting at King’s College London.
The title of this post refers to an Adam Curtis documentary series from 2011, itself taken from a Richard Brautigan poem. I’ve reproduced the last stanza:
I like to think
(it has to be!)
of a cybernetic ecology
where we are free of our labors
and joined back to nature,
returned to our mammal
brothers and sisters,
and all watched over
by machines of loving grace.
This is a lyric expression of something that’s come to be known as Technological Utopianism. This isn’t merely the preserve of beatniks and hippies; Bertrand Russell wrote, in his 1932 essay In Praise of Idleness, “four hours’ work a day should entitle a man to the necessities and elementary comforts of life, and that the rest of his time should be his to use as he might see fit,” because:
Leisure is essential to civilization, and in former times leisure for the few was rendered possible only by the labors of the many. But their labors were valuable, not because work is good, but because leisure is good. And with modern technique it would be possible to distribute leisure justly without injury to civilization.
And John Maynard Keynes wrote, in his 1930 essay Economic Possibilities for our Grandchildren, that within 100 years the “economic problem” would be solved. In 2030 we would all be working “three-hour shifts or a fifteen-hour week” and:
For the first time since his creation man will be faced with his real, his permanent problem-how to use his freedom from pressing economic cares, how to occupy the leisure, which science and compound interest will have won for him, to live wisely and agreeably and well.
Keynes’s grandchildren are eleven years from this horizon, and (needless to say) things haven’t quite worked out that way. Why not?
Russell’s “Modern technique”

The Jacquard Loom in the Musée des Arts et Métiers in Paris [Moof (CC BY 2.0)]
Those punched cards may look familiar to computer users of a certain age; they are practically identical to those once used to program computers. The comparison is not lost on the curators of the museum; the exhibition leads finally to a room containing a Cray 2 supercomputer. Nor was it lost on Charles Babbage, who understood punched cards could be used to program his Analytical Engine.

A fifteen hour week?
The textile industry gave Britain its first full-blown industrial relations crisis: the outbreak of machine breaking by the Luddites. The Luddites were not, contrary to popular opinion, opposed to technology per se; textile workers had been using stocking frames since Tudor times, but in a highly-regulated industry. The Luddites’ machine breaking was instead a response to the use of machinery in “a fraudulent and deceitful manner,” particularly by unskilled apprentices working without the supervision of master craftsmen. In Eric Hobsbawm’s memorable phrase, the Luddites were conducting “collective bargaining by riot“.
The textile workers’ expertise, hitherto distributed among men and machines in a cottage industry, became concentrated in machines housed in factories owned by capitalists.
Did the textile workers share in the profits that followed? Did they reduce their hours to fifteen a week? Of course not:
[Wages] could be compressed by direct wage-cutting, by the substitution of cheaper machine-tenders for dearer skilled workers, and by the competition of the machine. This last reduced the average weekly wage of the handloom weaver from 33s. in 1795 to 4s. 1½d. in 1829.
Eric Hobsbawm, The Age of Revolution: Europe 1789-1848
In thirty four years, their wages were reduced to one eighth.
So much for history
This is not a phenomenon confined to the pages of history books. A similar battle is playing out right now, on the streets of London, between black cab drivers and Uber.
In order to become a cabbie, you need “the knowledge,” earned by learning 80 runs across the city, getting at least 60% on two written exams, and passing three oral exams. This can take between three and five years to accomplish. By contrast, becoming an Uber driver in London requires that you have a TfL Private Hire license, and I estimate this to take a minimum of eight weeks. The process includes what TfL calls a “topographical skills assessment“, which (being brutally honest) ensures you are able to read a map.
It is very difficult to find out the earnings of black cab drivers or Uber drivers, because they are self-employed and not required to reveal their earnings to impertinent systems administrators. But the New York Times estimates Uber fares to be about 30% cheaper than black cabs, and Uber extracts a fee upwards of 25% from its drivers. As Daniel Markovits, author of The Meritocracy Trap, points out, a cabbie can earn enough to own a home, provide for his family, and go on holiday. The precarious finances of the Uber driver, on the other hand, are legendary.
Naturally all this enrages the black cab drivers; as with the looms in the dark satanic mills of the 19th century, their previously distributed expertise is becoming concentrated in the machines of capitalists.
But this time, there are no looms to smash. Uber has developed not one machine learning algorithm, but so many that their engineers have created a bespoke machine learning service, so the teams of engineers working on the myriad components of the Uber service can automate them more easily.
So they want to replace you with a machine. But is it any good?
Models used in forecasting have a property called “skill”, which measures how good they are at what they’re intended to do. I’d like you to consider a specific example which, while detailed, is readable enough for a non-technical audience. Amazon Web Services will rent you a machine learning service, which you can bend to your requirements. In this example, Denis Batalov shows how you can use Amazon Machine Learning to predict customer churn from a mobile phone service.
For mobile providers, obtaining new customers is costly. Those special offers you see advertised are loss leaders designed to lure you into signing a contract. They will absorb the loss because they assume you are too lazy to switch providers at the end of your contract, at which point they can milk you for profit. Those customers who do leave are said to “churn”.
The set uses comparatively few data points, for example how long the customer has had the service, how much they use their phone, how much the service costs and how many times they’ve called Customer Services. The goal of the exercise is to identify those customers most likely to churn, and to stage an automated intervention, buttering them up with free minutes, a new handset, etc.
The algorithm is trained first on data where it can see the outcome. Customer x with the following attributes remained a customer, but customer y with these attributes decided to leave. Then, to test its skill, it is shown the data without seeing the outcome. More successful models are selected for evolution, and the remainder are culled. This continues until the returns are diminished to the extent that there’s no more tweaking to be done.
As you can see, 14.5% of customers in the set “churned”. Can the machine identify those who will stay, and those who will leave? Well, it can identify 86% of them. But this is, in practical terms, the same as having no model at all, or (to put it another way) having a model which assumes all customers are loyal but is wrong about 14.5% of them.
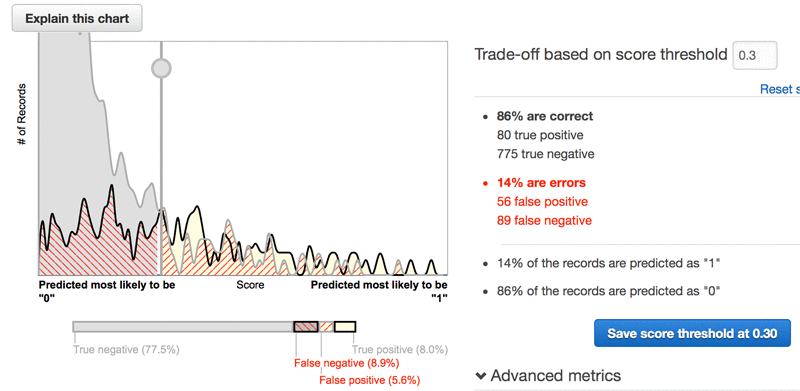
However, since losing customers is expensive, and offering butter-ups is (comparatively) cheap, you can tweak the model so that it is more wrong than having no model at all, and yet saves the company $22.15 per customer. Scaled up, this is big money (and a big bonus for the ML developer).

Less accurate than guessing, but much more profitable.
What has this to do with Learning Technology? I’ve seen ML models not very different to the above, deployed in a VLE and using very few data points, making predictions about whether a student will pass or fail a particular module, or whether a student will drop out or remain enrolled. The problems come in the “costs” we attach to the quadrants in the truth table, and in concentrating expertise in a machine at the expense of our distributed expertise as individual educators.
Seen it all before
Any forecasting discipline also suffers the problem of bias. In human actors, we hope it is unconscious. But in machine learning, it is built in, because we are training our AIs on historical data.
In 2017, Amazon announced it had shuttered an experimental programme to train an AI for recruitment. Scouring LinkedIn or sifting a pile of applications is time-consuming (and thus costly), repetitive, boring, and tiring. These characteristics belong to tasks which IT professionals immediately select for automation. But, just as when training a model to predict customer churn, historical data are required, with all the perils inherent therein. Amazon’s AI was chucking women’s applications on the discard pile, because the company had, in the past, consistently favoured male applicants over female ones.
Again, what has this to do with learning technology, or even with IT in HE? I’ve found institutions which were at least toying with the idea of using machine learning to sift admissions applications. What will that do to our efforts to widen participation? Instead of artificial intelligence, we will have automated ignorance.
When you combine bias-as-code with the kinds of de-skilling discussed in the cases of the textile workers and taxi drivers, you have a potent recipe for problematic decision making. The most recent example is the “sexist AI” behind Apple Card, which assessed a married couple who, on the face of it, presented identical credit risks. It offered the husband 20x the credit limit it offered his wife. Apple’s customer services people threw their hands up: “It’s just the algorithm”. Even The Woz waded in, observing “It’s hard to get to a human for a correction though. It’s big tech in 2019.” Once again, we see expertise, previously distributed among financial advisers, concentrated in a machine.
Weird, inscrutable logic
Even if Apple had retained the human capability to consider an appeal against the AI’s decision, it wouldn’t have been able to explain that decision, because ML algorithms do not admit of human scrutiny: software that is evolved is unreadable.
As a systems administrator, I like code that can be audited. When something aberrant happens, I like to be able to see if there’s a logic problem. But in discussions with non-systems (i.e. normal) people, I’ve come to agree that it’s acceptable, in some circumstances, to audit a system only knowing its inputs and its outputs. An example is the pocket calculator. You can ask it to solve 5 x 5, 10 – 8, etc, and compare it with your own working. Eventually you come to trust the system and ask it to solve the square root of pi, and because it’s been right about everything until now, you believe that it’s right about this.
But as we’ve seen, ML is being asked to solve more complex problems than the root of pi. It’s being asked to make predictions and decisions, with multiple inputs that it may or may not be using to draw its inferences, some of which could be wildly inappropriate. There are, after all, a lot of spurious correlations in the world.
So I finish on an appeal: if your institution is ever considering the use of AI to admit applicants, or mark students’ work, or predict their likely success, press as hard as you can for the institution to retain a human in the process. Because if the past is any guide — and it surely is, because that’s the basis on which we’re training our machines — if you don’t, there won’t be anyone left to hear an appeal.




{kind=link}
{kind=link}
[…] Chris Fryer, senior systems administrator at LSE, then gave a talk about previous industrial revolutions and associated progress or otherwise; and gave us a reality check about the likely benefits of the 4th industrial revolution. Chris had some superbly cautionary tales about using AI to make predictions and decisions, with some heavily biased outcomes for the humans on the receiving end of the decisions. He won ‘best line of the day’ with his observation that AI was currently less artificial intelligence and more ‘automated ignorance’ and he finished with an appeal to ‘press as hard as you can for [your] institution to retain a human in the process’ (admissions, marking, etc.). Read his excellent blog post ‘All watched over by machines of cold indifference’ here. […]
[…] Concluding the afternoon, we welcomed Chris Fryer (Senior Systems Administrator at the London School of Economics and Political Science) who provided a different lens on Education 4.0 and gave us a cautionary insight into what we can learn from a history of automation and mechanisation. Chris has blogged about his talk in the LSE Learning Technology and Innovation Blog. […]
[…] Concluding our sessions for the afternoon, we welcomed Chris Fryer (Senior Systems Administrator at the London School of Economics and Political Science) who provided a different lens on Education 4.0 and gave us a cautionary insight into what we can learn from a history of automation and mechanisation. Chris has blogged about his talk in the LSE Learning Technology and Innovation Blog. […]