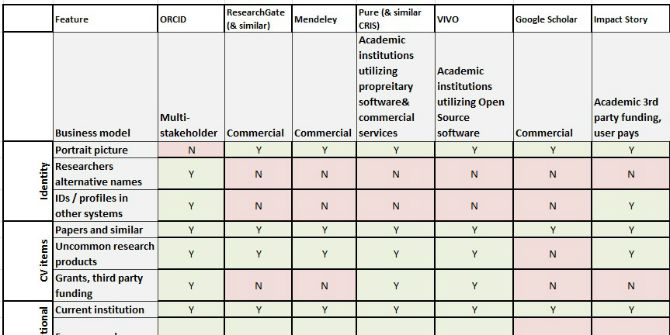
 There remains something of a disconnect between how research librarians themselves see their role and its responsibilities and how these are viewed by their faculty colleagues. Jeannette Ekstrøm, Mikael Elbaek, Chris Erdmann and Ivo Grigorov imagine how the research librarian of the future might work, utilising new data science and digital skills to drive more collaborative and open scholarship. Arguably this future is already upon us but institutions must implement a structured approach to developing librarians’ skills and services to fully realise the benefits.
There remains something of a disconnect between how research librarians themselves see their role and its responsibilities and how these are viewed by their faculty colleagues. Jeannette Ekstrøm, Mikael Elbaek, Chris Erdmann and Ivo Grigorov imagine how the research librarian of the future might work, utilising new data science and digital skills to drive more collaborative and open scholarship. Arguably this future is already upon us but institutions must implement a structured approach to developing librarians’ skills and services to fully realise the benefits.
Imagine research librarians as equal partners in the research process, helping a researcher in any discipline to map existing knowledge gaps, identify emerging disciplinary crossovers before they even happen, and assist in the formulation and refinement of frontier research questions.
Imagine a librarian armed with the digital tools to automate literature reviews for any discipline, by reducing thousands of articles’ ideas into memes and then applying network analysis to visualise trends in emerging lines of research.
What if your research librarian could then dig deeper and use an ami-2word plug-in to map in which sections of articles your key research terms appear? Imagine the results confirmed that your favourite research term almost never appears in the results sections, but cluster only around introductions and perspectives.
 Image credit: Imagine… by Gabi L. This work is licensed under a CC BY 2.0 license.
Image credit: Imagine… by Gabi L. This work is licensed under a CC BY 2.0 license.
And what if the librarian did not stop there, but zoomed into the cloud of data with savvy statistics, applying the latest text and data mining techniques to satisfy even the most scrutinising scientific mind, before formulating an innovative research question?
Imagine a librarian who understands, in pragmatic terms, the benefits of Open Science to the discovery process. Imagine a librarian who also has practical advice on how to make those ideas part of your daily workflow. Would you like that librarian to help you kick-start your academic career?
It may sound too good to be true, but in a way it is already happening.
Core duties versus ‘stretch’ services
The research librarian community is not in consensus as to what exactly are the emerging roles of future librarians in a rapidly evolving digital scholarship environment (see #libraryfutures). Added to the polarised views within that community, a recent survey shows there is also a clear gap in perception and expectations between librarians and faculty staff. While librarians surveyed agreed that “information literacy” and “aiding students one-on-one in conducting research” are primary and essential roles, they viewed “supporting faculty research” as less important than their faculty colleagues. So does this present an opportunity in the digital age?
Librarian as co-investigator, not an overhead
In the digital age, many of the skills and competencies librarians develop to perform ‘core’ services can actually directly serve the research lifecycle and workflow. Competencies such as mapping the knowledge landscape, digesting volumes of heterogeneous data or presenting in understandable formats are not things every researcher is armed with but which every hypothesis can benefit from.
By using their data science and digital skills, research librarians have the opportunity to make an impactful contribution to the workflow of their faculty colleagues. Librarians’ data science skills can help navigate through the deluge of information, and can truly change how they are perceived: from an overhead service to research co-investigators.
Despite the opportunities, it would be easy to frustrate the community of librarians by calling for a skills upgrade without contributing in small steps to filling any skills gap. If data science skills are not part of an institution’s strategy, it is difficult to find time and resource to upgrade an individual’s skillset while fulfilling existing contractual obligations. This is where existing structured training philosophies can help with both skills and convincing institutional managers of the strategic benefits of boosting data science capacities. Some examples of data science training include Data Carpentry, Data and Visualization Institute for Librarians, Library Carpentry, Data Science Training 4 Librarians and there are likely many others too.
Data science as a driver of Open Science by default
As the need for more open and transparent scholarship permeates through funder mandates, research librarians become an indispensable partner in optimally disclosing the diverse outputs of the research process; from advice on choice of appropriate licenses for re-use, to best long-term curation and persistent identifier (PID) assignment in synergy with existing intellectual property rights practices.
But to keep in step with the trend, “librarians must provide research data supporting services in the digital age”, and institutions need a structured approach to “enhance research librarians’ data skills, RDM & data services”. The data science skillset of librarians is also considered by some graduate schools (e.g. those engaged with FOSTER Project 2014-2016) to be a deciding factor if Open Science is to form part of the standard skillset taught to postgraduates.
To meet Open Science implementation needs, calls for the boosting of institutional data skills extend across disciplines (NSF-NITRD Federal Big Data Research & Development Strategic Plan, May 2016) further downstream to “new skills in data science, data analysis and visualisation” and “text and data mining of content”.
Making the future librarian an indispensable research partner to faculty would not only close the gap in how the role is perceived, but also create a self-sustaining conduit for including best practices in collaborative and open scholarship, and implementing Open Science by default. Ultimately, everyone would get more impact.
Note: This article gives the views of the authors, and not the position of the LSE Impact Blog, nor of the London School of Economics. Please review our comments policy if you have any concerns on posting a comment below.
About the authors
 Jeannette Ekstrøm holds a Master of Library and Information Science from the Royal School of Library and Information Science, Copenhagen and has been working with information literacy, user education and openness at DTU Library. Jeannette coordinates Data Science Training 4 Librarians in the EU in 2015 and 2016 (@DST4L) and can be followed on Twitter at @JEkstroem.
Jeannette Ekstrøm holds a Master of Library and Information Science from the Royal School of Library and Information Science, Copenhagen and has been working with information literacy, user education and openness at DTU Library. Jeannette coordinates Data Science Training 4 Librarians in the EU in 2015 and 2016 (@DST4L) and can be followed on Twitter at @JEkstroem.
 Mikael Elbaek holds a Master of Library and Information Science from the Royal School of Library and Information Science, Copenhagen and is the coordinator of the Research Data Management Team at Technical University of Denmark. He has been a strong advocate for openness in science and been involved in policy development and infrastructures since 2005. Mikael can be followed on Twitter at @melbaek.
Mikael Elbaek holds a Master of Library and Information Science from the Royal School of Library and Information Science, Copenhagen and is the coordinator of the Research Data Management Team at Technical University of Denmark. He has been a strong advocate for openness in science and been involved in policy development and infrastructures since 2005. Mikael can be followed on Twitter at @melbaek.
 Chris Erdmann holds a Master of Library and Information Science from the University of Washington iSchool and a BA from the University of California, Davis. He is the Chief Strategist for Research Collaboration at the NCSU Libraries, and he formulated the Data Science Training 4 Librarians curriculum in 2014. Chris can be followed on Twitter at @libcce.
Chris Erdmann holds a Master of Library and Information Science from the University of Washington iSchool and a BA from the University of California, Davis. He is the Chief Strategist for Research Collaboration at the NCSU Libraries, and he formulated the Data Science Training 4 Librarians curriculum in 2014. Chris can be followed on Twitter at @libcce.
 Ivo Grigorov is an Open Science enthusiast and research coordinator at Technical University of Denmark. As a member of the FOSTER Consortium, he advocates for the strategic and career benefits of Open Science to both individuals and research institutions. Ivo can be followed on Twitter at @OAforClimate.
Ivo Grigorov is an Open Science enthusiast and research coordinator at Technical University of Denmark. As a member of the FOSTER Consortium, he advocates for the strategic and career benefits of Open Science to both individuals and research institutions. Ivo can be followed on Twitter at @OAforClimate.




What is it that research students can’t do that research librarians can? I suspect that like typists the research librarian will become extinct.
I mean if you want to take the time to train graduate students for a couple years in skills that librarians already possess and lose all of their accumulated knowledge each time they graduate or move on…I guess nothing?
What research librarians can do that research students can’t varies depending on the individuals involved. Typically, however, you may find that librarians have a different set of skills regarding finding research information as well as specialist skills and knowledge relating to areas such as open access publishing, research data management, bibliometrics, copyright, delivering training – all of which are relevant to research.
It is not to say that other people could not develop these skills but then you could say that, theoretically, pretty much anyone can develop pretty much any set of skills given the right circumstances.
On this basis, could we not re-phrase your question as “what can researchers do that research librarians can’t” (i.e. “what can anybody do that anybody else really couldn’t”)?
My only worry is whether our LIS schools are complying with these emerging trends. Do our current LIS students getting these skills of say, data carpentry, library carpentry, data science to mention but a few
I enjoyed this article. What is interesting to me is all of the skills and activities noted here have been a part of special librarian’s roles for years now. It would be amazing to get more skills like this in typical library roles but hiring managers are not “in-tune” with this yet.
Short answer to David’s question, quite a lot. Information and data in the abstract, have many attributes that can be leveraged and exploited to exact discovery. This is a specialized skill set that comes with training across disciplines and a certain time-in-grade real world experience, in the context of service. Extinction is for those that do not adapt nor recognize the possibly one can. At the end of the day, what was old is new again. v2 – volume and velocity on information, as with the brain’s ability to discern, parse and absorb the same, is akin to Moore’s Law. The problem is TMI and intellectual laziness… viz `a viz expediency. Librarians can and do help people all the time with this and other problems, across all media. They just don’t get much credit for it with the selfie-generation, or that of the me, myself & I crowd. “It’s all online”…good luck with being a stooge to filtered bots, let alone digitally dependent in a post-EMP future…save the books, read more, learn something new. Ask a librarian for help. Cheers 😉 –Bob, supervisory research librarian
A complimentary idea by Jonathan Gray, suggesting that in a Digital Age libraries could be bastions of democracy and “spaces for democratic deliberation and social participation around the creation of data and around processes of datafication”, Datafication & Democracy, Dec 2016, http://www.ippr.org/juncture/datafication-and-democracy
If this means that we researchers no longer have to build complex live repositories ourselves from scratch (as we were forced to) and have livrarians welcone researchers with real input into the eScholarsjip domain, this would be excellent news. Experoence over the last twenty years with multiple iniversities suggests otherwise. I look forward eagerly to being proved wrong t-his time! Cant wait!
I agree there is an opportunity here, backed up by the ‘Closing the Gap’ survey you have quoted. Sad to see these results, actually, especially things like: while 64% of faculty see it as essential or very essential for the library to coordinate research data services only 49% of librarians thought so. It would be worth digging alot deeper to find out exactly why some libraries – and some librarians – are more willing to incorporate data science skills and training and others are not. I don’t think it is just the ‘prioritising students’ factor, there’s probably a strong element of cultural and personal resistance to change (esp. tech change) – no doubt among other factors.
Cultural and personal resistance is a significant factor, not just at individual level, but also at institutional level. If managers do not support their staff with time and resources to re-train with the times, skillsets lag behind. In the fast evolving Digital Age, it is easy to lag behind.
But individual resistance, “tech fobia” are also significant. An indicatord of this is the polarising debate on redefinition of librarian core services versus emerging challenges, and how proactive should librarians be towards faculty (e.g. discussion on #libraryfutures on Twitter)
I question whether research librarians should be trying to get data science skills. Data science is not easy and requires a lot of study and practice (on your own time). Unless they take the time to properly learn it, how can they help researchers? Knowing a bit isn’t helpful, you must know a lot. In fact you might as well become a data scientist if you know that much that you can do data analysis and visualisation. And if you do have data science skills as a librarian, you rarely get the chance to use them. I’m not using my skills and they’re not getting any better as a result. This is something that’s bothered me for a while.