 Political polling has faced difficulties during recent elections. Drawing on methods used for US elections and elsewhere, Philippe Mongrain proposes a new forecasting model, which takes into account the state of the economy, the cost of ruling for the incumbent party, leadership approval ratings and previous election results, and offers some improvements on existing polls for forecasting the vote share of all contending parties.
Political polling has faced difficulties during recent elections. Drawing on methods used for US elections and elsewhere, Philippe Mongrain proposes a new forecasting model, which takes into account the state of the economy, the cost of ruling for the incumbent party, leadership approval ratings and previous election results, and offers some improvements on existing polls for forecasting the vote share of all contending parties.
In recent years, the British polling industry has encountered difficulties in its attempts to forecast party vote shares in important elections, notably the 2014 referendum on Scottish independence, the 2015 UK general election, and the 2016 EU membership vote. There is a value therefore in exploring possible new forecasting models that use political and economic variables – rather than vote intentions – to predict the outcome of electoral contests. Political scientists have been forecasting the results of presidential races and congressional campaigns in the United States for nearly 40 years now. Scholars have also developed models to predict the outcome of national elections in France and Germany.
The UK has received some attention from forecasters, though the models proposed in the 1980s and 1990s were somewhat different than US ones. In fact, the predictive equations from that period (see, for example, Whiteley 1979; Sanders 1991; 1993; 1995; 1996) were almost all designed to predict vote intentions (or ‘popularity’) instead of actual vote shares. However, forecasting vote intentions and vote shares are two very different endeavours. Mughan (1987) was the first scholar to make this point, but also to propose a comparison between three simple forecasting models for British general elections that would estimate the electoral performances of the incumbent party and the official opposition as well as the scores of the SDP–Liberal alliance for the 1987 race.
The recent growth of election forecasting in the UK
After Mughan’s 1987 paper, it took more than 15 years before new ‘structural’ forecasting models – i.e., models relying on macroeconomic and political variables – for British elections were published. These new structural models were in large part due to the work of two teams of forecasters. The first, Lewis-Beck, Nadeau, and Bélanger (2004; see also 2005; 2009), proposed equations that incorporated variables intended to capture the notions of retrospective voting and attrition of power as well as the level of competitiveness of the leading parties. The second team was made up of Lebo and Norpoth (2007, 2011, 2013, 2016; see also Norpoth 2004). These scholars put forth autoregressive equations that are primarily based on the concept of ‘electoral cycles’ (see Norpoth 2014). The idea of the ‘electoral cycle’ refers, first to the partial inertia of the vote, which allows the governing party to maintain a more or less important part of its support. Second, modelling ‘electoral cycle’ effects takes into account the gradual shrinking of the government’s support pool due to the growing psychological weariness felt by citizens towards the incumbent party after a certain amount of time. More precisely, Lebo and Norpoth’s modelling strategy is designed to ‘[capture] the swing of the electoral pendulum’.
A new model
Despite the variety of existing forecasting models for British general elections, there are few that rely on economic and political variables and/or vote intention data going back to the 1950s in order to predict the vote shares of all the contenders. Most existing models either exclusively focus on the vote shares of the incumbent party or try to estimate the results of multiple parties by looking only at a handful of electoral contests. For this reason, for a new research note published by the Journal of Elections, Public Opinions and Parties, I developed a set of seemingly unrelated regressions (SUR) that takes advantage of almost 60 years of data in order to predict the vote shares obtained by the incumbent party, the official opposition, the Liberal Democrats (or the Liberals and the SDP–Liberal alliance before the 1992 election), and all remaining parties. At least four conclusions can be drawn from existing structural models in the UK, that is (1) there is a static or cyclical dimension to voting; (2) the incumbent party’s vote share on election day depends on incumbent approval; (3) the level of support for the party in office is influenced by the state of the economy just before the vote; and (4) the longer a party stays in power, the more it risks losing votes due to citizens’ fatigue and their eventual yearning for change. I took these points into account in developing my own forecasting model. Our equation for forecasting the vote shares of the incumbent party includes four variables that directly translate each of these conclusions. They are:
-
-
- the percentage of the popular vote received by the incumbent party in the previous election;
- the approval/satisfaction rating of the Prime Minister in the third month preceding the month of the election;
- the GDP growth rate in the second quarter before the election quarter; and
- the number of consecutive months spent in office by the incumbent party.
-
Using a three-month lag follows a practice that is common in recent American election forecasting. The equation for the main opposition party is based on two independent variables, namely:
-
-
- the approval rating of the official opposition leader; and
- the percentage of vote intentions garnered by the main opposition party in relation to the other opposition parties (the ‘opposition vote monopoly’).
-
The logic here is that the more the largest opposition party is able to monopolise the overall opposition vote, the better it will perform on election day. The equation for the Liberal Democrats is based on the vote intentions they received in the third month before the election month and the vote share they got in the last election. The remaining competitors’ equation is solely founded on their overall vote intentions three months before the election.
Not only do the effects of the variables used to construct the model conform to our expectations, but the variables themselves explain an important proportion of the variance in the popular vote shares received by the parties (more precisely, between 71% and 88% of the variance). Larger vote shares in previous elections, economic growth and high levels of satisfaction with the way the Prime Minister is doing his or her job benefit the incumbent party, while the number of months spent in power has a negative (albeit modest) influence on its performance. The approval rating of the leader of the opposition and the ability of the main opposition party to ‘monopolise’ opposition vote intentions are related to stronger showings at the polls for the official opposition. The results of the Liberal Democrats are positively related to their share of vote intentions as well as their past election scores. Finally, the remaining smaller parties’ vote shares appear to be closely related to their combined performance in vote intention surveys. Furthermore, the proposed model turns out to be quite accurate, particularly in the cases of the incumbent party and the smaller competitors. Looking at out-of-sample forecasts (which are obtained by removing from the equations the data associated with the election for which we want to estimate the outcome), our SUR model performs slightly better than poll-based projections made three months before the election. Forecasts uniquely based on the average of vote intentions for a party between 1959 and 2017 render mean absolute errors (MAEs) of 2.75, 2.99, 3.25, and 2.19 percentage points for the incumbent party, the official opposition, the Liberal Democrats, and the remaining parties respectively, compared to 2.28, 2.64, 2.98, and 2.17 percentage points for the SUR model. Figures 1 through 4 show the absolute out-of-sample MAEs for each election and each party for the SUR model and poll-based projections.
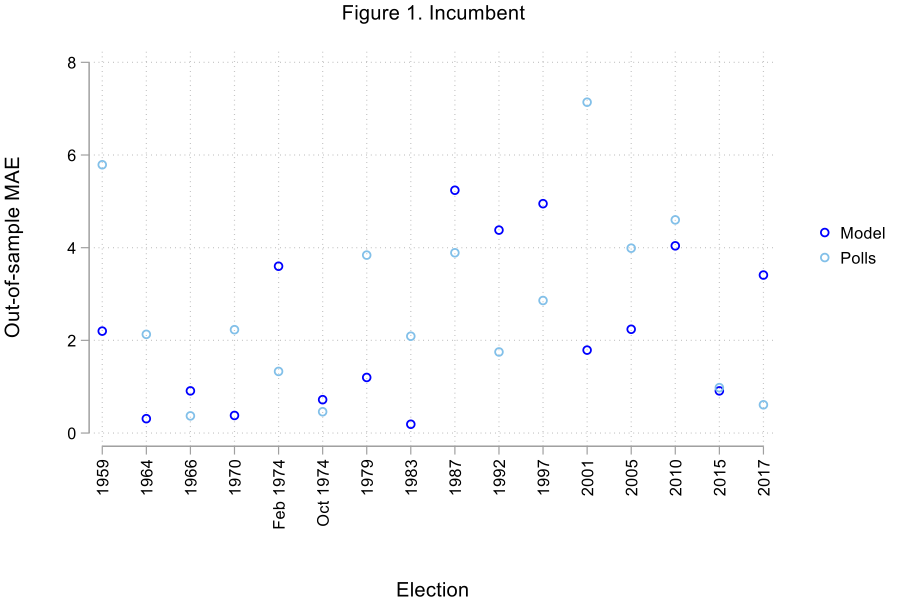
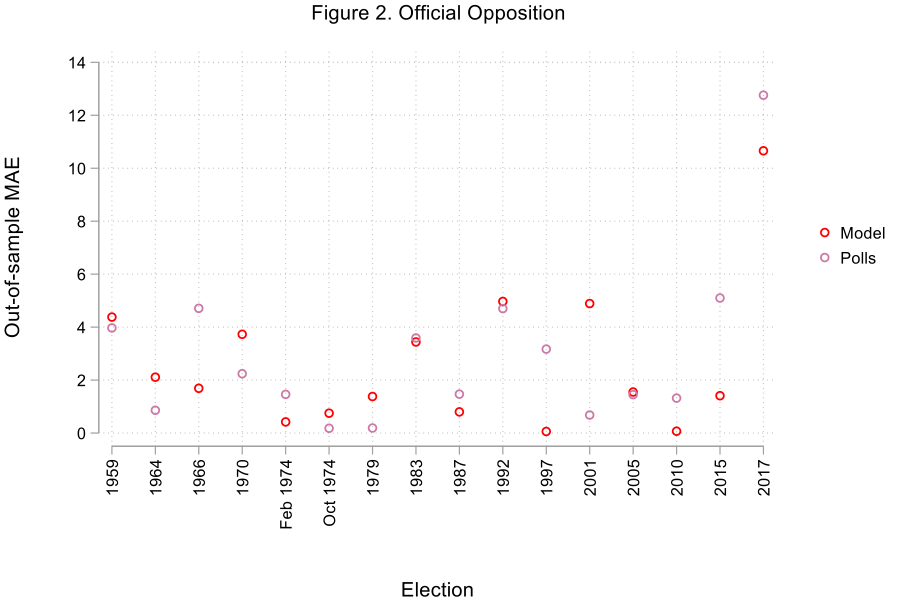
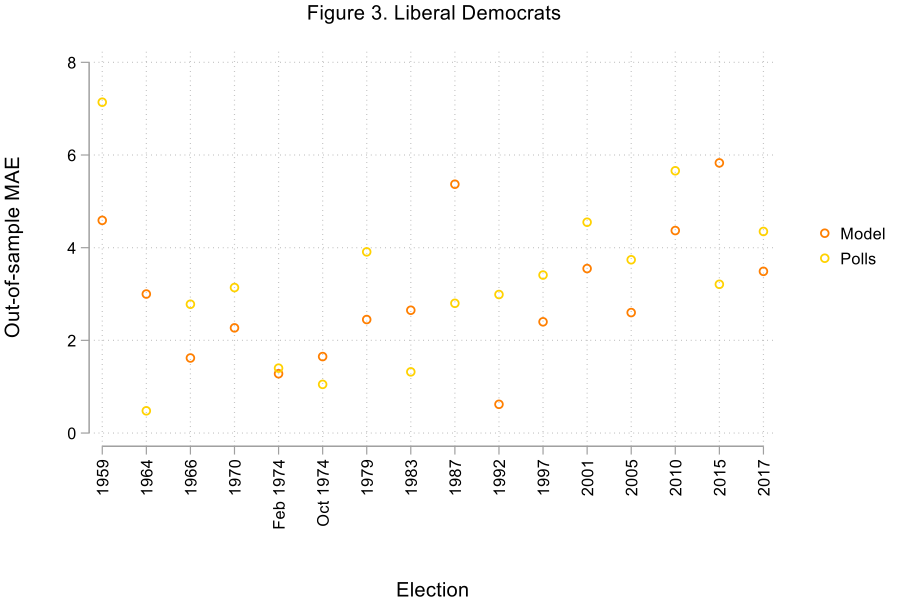
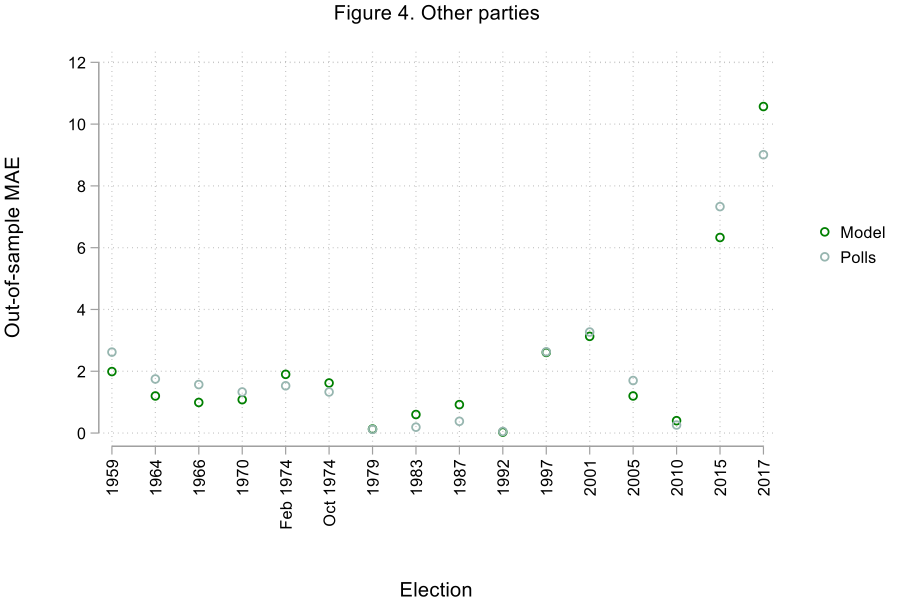
Conclusion
With a three-month lead, our model offers accurate forecasts for the three main British parties and their remaining competitors. It does so by integrating variables that are important to political science – the state of the economy, the cost of ruling, approval ratings and election results themselves. However, this model is designed to forecast the popular vote. In most legislative contests across Western democracies, votes are not (at least not exactly) what makes a party (or coalition) win an election. Seats are. Predicting seat shares is fraught with difficulties, especially in first-past-the-post (FPTP) systems such as the UK where there are usually high levels of disproportionality between the national share of the votes won by a party and its share of seats. Different ways to forecast seats have already been proposed and future research should devote more attention to that subject.
The polling industry has had to confront some major mishaps during the last few years that has shaken the confidence of citizens in pollsters’ ability to forecast election outcomes. Hence, it is important to propose new models and methods to demonstrate how election results (and perhaps the results of other forms of political consultations) come about. From an epistemological standpoint, it is also important to show that political science is not limited to ex post explanations of political events. Social scientists should not shy away from trying to forecast human behaviour and collective decisions.
________________
Note: the above was first published on Democratic Audit. It draws on the author’s research note published in the Journal of Elections, Public Opinion and Parties.
Philippe Mongrain is a PhD student in Political Science at the Université de Montréal (Canada) and a member of the Canada Research Chair in Electoral Democracy. His work on election forecasting has been published in the Canadian Journal of Political Science, the Journal of Elections, Public Opinion and Parties, and Research and Politics. His research interests include Canadian politics, economic voting, and election forecasting.


