
Much of public opinion polling in the UK is nowadays conducted online. This has many advantages as it allows polls to be conducted more cheaply, but it also runs into several problems. Thiemo Fetzer (University of Warwick) illustrates some of the technical issues that arise using the example of the British Election Study, which is an important point of reference for much UK political science research. The analysis suggests that repeat participation in the BES panel may systematically skew the implied Leave/ Remain split in favour of Leave. While there are many reasons behind this, the industry should increase transparency and develop access protocols for underlying micro-data. This could be a positive turn in industry self-regulation and spur innovation and development in the sector.
1. How conventional polling works
Opinion polling is an industry that has seen a lot of changes in the last few decades. The core idea of polling is simple: in order to make inference about “what a population thinks”, one only needs to ask a representative sample. If the sample is genuinely randomly selected (to avoid selection bias) and representative (this is usually implicit in random sampling), then the sample average of, for example, support for Leave versus Remain, should be representative for the population at large. There are variations of this approach, but in the end this is the core idea. To make inference about the population, individual observations within a sample then get weighted based on how “common” their vector of socio-economic characteristics are in the population.
In the past, much of opinion polling was done through a process called Random Digit Dialling, whereby random set of households were called to express their view. A lot of opinion polling in the US is still conducted in that fashion. Yet, the decline of landline phone use, along with lower propensity to answer or engage with an interviewer make this method of sample recruitment ever more difficult. Another alternative is intercept surveys e.g. in public places (this is how the ONS Passenger Surveys are constructed). A third way is to physically knock on people’s doors. It is clear, that each of these latter methods are much more costly.
The fact that opinion polls themselves have an impact on political participation and potentially even on voting should not surprise anyone – and there is good research evidence highlight that polls have a feedback effect on participation. As such, opinion polls become a tool of political influence, are not only a tool to inform the electorate, they may also influence choices.

2. Opinion polling today
Most polling conducted in the UK today uses online polling. YouGov and Survation are among the pioneers in this sector and they have definitely pushed the technological envelope here. The way these platforms operate is to conduct opinion polls online. Rather than drawing from the population at large, they work with a community of members who have signed up to participate in their surveys – and, end up getting paid for this. In the case of YouGov, in the UK the platform has 1.2 million members. The opinion polls are conducted exclusively on these 1.2 million members who are paid to participate. If these 1.2 million members are not representative of the population at large, then there is a risk that naïve application or construction of sample weights may not overcome the implicit sample selection bias. Further, we do not even know what the nature and source of the sample selection bias is.
How samples are recruited on these platforms is a bit of a black box. There is a risk that the platforms may be flooded by political activists, or foreigners living in low-income countries (such as many clickbait and fake news producers) or even hostile foreign interests. I personally have signed up to both YouGov and Survation and have participated in a few polls about UK politics to highlight this issue. The fact that I am not a naturalized British citizen and technically, have no right to vote in the UK (yet) did not matter. Similarly, there was no issue with assigning myself a very common Russian name. It also wasn’t an issue I had used a VPN service that made my IP address to appear as if I am physically located in St Petersburg in Russia. I have closed the accounts since then, but this is merely to highlight that these systems are not necessarily sufficiently shielded and protected. Transparency and improved industry self-regulation could potentially offer such protection.
Unfortunately, researchers and academics, that develop many of the most buzzing new tools that are then marketed by opinion polling companies, such as Multilevel Regression and Postratification (MRP), have limited access to the data – this genuinely hampers innovation and undermines transparency. In the United States, industry self-regulation is much more advanced compared to what the British Polling Council requires of its members. The Roper Center for Public Opinion Research, for example, collects micro data from opinion polling companies and makes it available to academics. It is financed by a subscription service and hence, comes at limited cost to opinion polling companies. I do hope some initiative like this will see the light of day in the UK as well.
3. Patterns in British Election Study
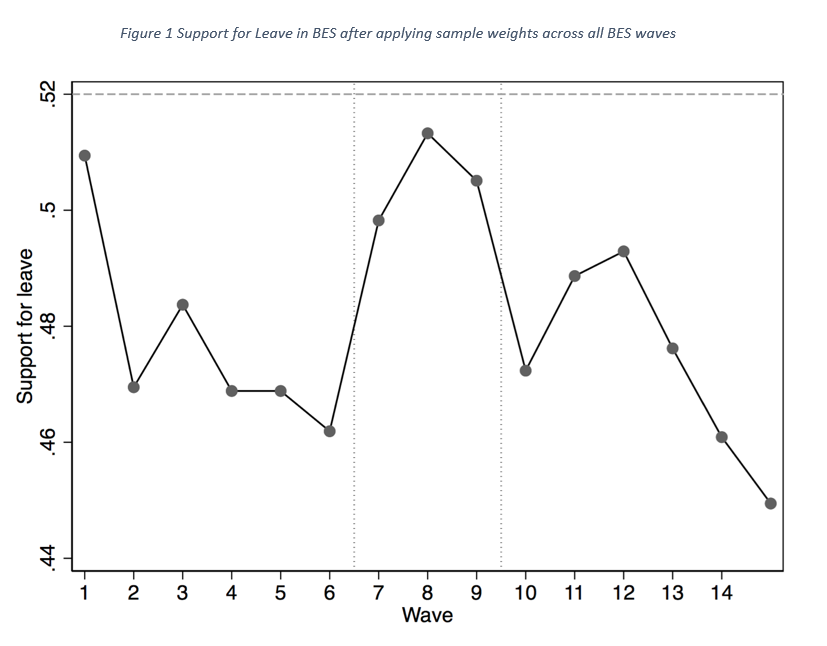
The British Election Study is a rare exception allowing academics a glimpse into the underlying YouGov micro data. Since 2014 it has been conducted on the YouGov platform, with the associated micro data made available for researchers. Figure 1 below plots support for Leave across the 15 BES waves in which the question was asked. Excluding “don’t knows” and using the survey weights provided, support for Leave in the YouGov administered British Election Study never reaches the 52% of 2016. It gets close to 50% for Leave in and around waves 7, 8 and 9. Wave 7 was conducted in April/May 2016, wave 8 was conducted in May/June just before the referendum, while Wave 9 was conducted just after the EU referendum. Since then, support for Leave has steadily declined with Remain leading 55% to 45% — a 10 percentage point margin.
4. BES sample composition may skew Leave vs Remain split
So here is a working hypothesis: politically engaged people are more likely to be active on YouGov longterm and, they are different from the population at large. This has the potential to skew results in a way that conventional weighting may not tackle as there are two levels of selection bias. Is there evidence consistent with that hypothesis? One way to tackle this is to study which people are active on the YouGov platform and how they compare more ad-hoc participants. This only gets a bit closer to tackling the underlying issue as the comparison group still is the sample of people that have been, at some point, active on YouGov.
The BES panel study has been conducted since 2014 in now 15 completed waves. It turns out that among the 30,327 respondents that participated in wave 1 – around 2,437 or 8% have participated in each of the 14 waves in which the EU referendum question was asked. Another 2,757 have participated in 13 out of 14 waves – a combined 30% of the Wave 15 respondents participated in at least 10 waves.
But what is the distribution of Leave versus Remain between each of these groups of participants? The figure below is an attempt to shed some light on this question. The red line represents the overall weighted average of support for Leave of people asked in BES Wave 7 conducted just before the EU referendum. The blue line is the average that would emerge without using the sample weights – this suggests that weighting helps increase headline support for Leave in that wave by around 1 percentage points.
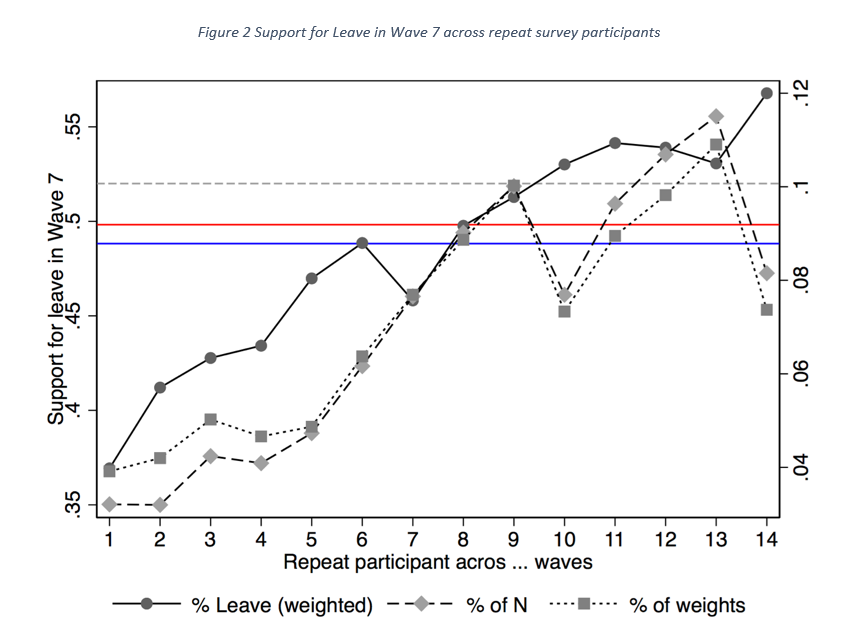
The solid line labelled as %Leave (weighted) computes the support for Leave versus Remain across the different cohorts of participants. The share of Leave versus Remain in each bin is weighted by the corresponding survey weights. This suggests that, indeed, the more likely you are to be a repeat YouGov participant, the higher the support for Leave. And, turning to the remaining lines, indicated on the second axis on the right, this group of repeat BES participants make up a larger share of both the sample and of the sample weights. The dashed line with diamond markers suggests that survey participants that took at least 10 out of 14 waves, make up 44% of the sample in terms of sample weights and, they make up 47% of the observations.
Among individuals that have participated in the survey at each point time the EU referendum question was asked, support for Leave is 56.8% – among individuals that only participated in that specific wave 7 (and never again) support for Leave is just 36.9% – a whopping 19.9 percentage point difference, suggesting that indeed, people who are repeat participants of the YouGov survey are significantly more likely to support Leave vis-à-vis the respondents that are less frequent on the platform.
This pattern, suggesting that more regular repeat YouGov BES participants are more likely to support Leave is stable – up until around Wave 13. From then onwards, the sample composition seems to change and include many more new recruits who have not participated in BES before. For example, individuals who have only participated in the single and most recent Wave 15 make up 15% of the observations but receive up 20% of the total weight. The noticeable result is that the overall weighted average of support for Leave now falls below the unweighted average (red line below the blue line). This suggests a major change that is also visible in the overall split with overall support for Leave starting to decline significantly from Wave 13 onwards as was highlighted in Figure 1.
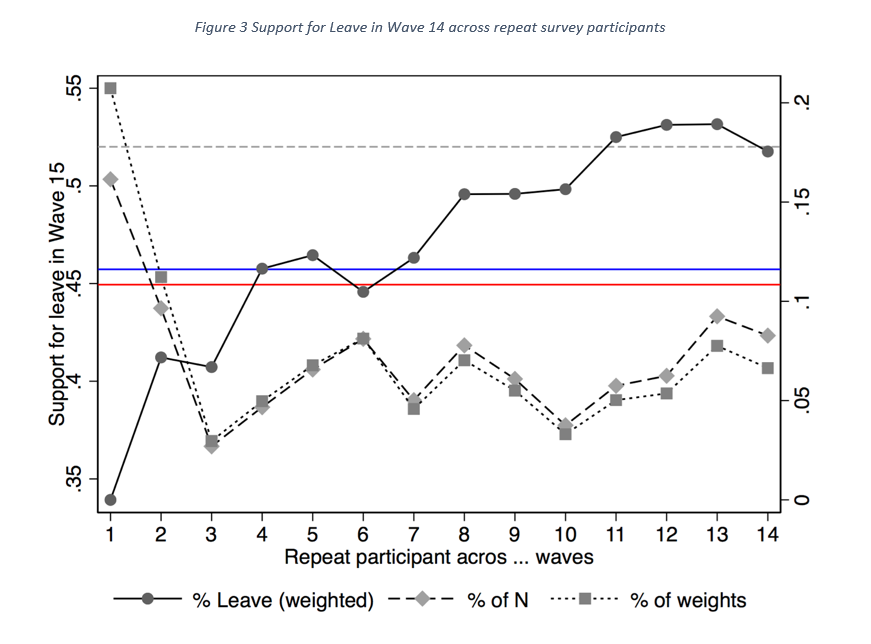
5. Very Regular BES participants appear more Brexity
We can study a set of socio-economic characteristics stand out among the set of respondents that participate (very) regularly in the YouGov panel. Below is a table that summarizes the main differences. Among the patterns that stand out: regular BES are significantly older. Among the (very) regular participants, 55% are aged 55 or above. According to the UK Census from 2011, the share of people aged 55 and older is only around 30% — this suggests indeed, that the regular participants are a bit odd. This difference is visible even after computing the sample averages using the provided weights, which should deskew things a bit.
Similarly, the (very) regular YouGov participants are much more likely to live in owner-occupied housing (12 p.p. difference), they are 22.6 percentage points more likely to be married and they are 17 percentage points more likely to be aged above 55. Similarly, they are much more likely to express to like Nigel Farage (scoring above 5 on a scale from dislike to like from 1-10). In a hypothetical 2nd referendum with the choice being No Deal or another Extension or with the choice being between Remain or No Deal, this group also stands out with a significantly larger share favouring No Deal.
If we study these respondents further – the sample that consistently participated in the BES waves appear indeed, much more pro-Leave and much more pro No Deal. Using the Wave 15 data which asks how people whether they would prefer to “Delay Brexit versus No-deal Brexit”, the respondents that participated at least 10 times, stress a preference in favour of No Deal of 54%. Among the respondents that participated less than 10 times, support for No Deal is only 42%.
Note these differences are all very large and hence statistically as well as economically speaking significant irrespective of the mode of inference. And they appear in the weighted, as well as, unweighted sample averages. Of course, there could be a common unobservable factor driving both, participation in the online poll as well as explaining these differences. Yet, controlling for a factor does not mean that the inherent sample selection bias implicit in participating in YouGov panels is tackled. What would be a significant step forward is for the industry to work more closely with academics and develop access protocols for academics to develop our understanding the economics and the impact of incentives that may drive the various forms of selection bias that could skew or affect results.

6. Within-individual variation in sample weight rank
Another interesting metric to evaluate the quality of polling is to assess the weights directly. The whole idea of applying sample weights is to ensure that the population is adequately represented. Unfortunately, the exact ingredients into how weights are computed are not provided. They are likely to be heavily drawn from a set of profile variables, such as age, educational attainment, homeownership, marital status, income, etc., which are regularly collected. How much weight an individual observation then gets within each BES survey wave depends on two factors: first, on how common the individual vector of attributes is in the population at large (i.e. how often a specific combination of age, educational attainment, residence status, income etc. appears in the overall UK wide population – a central input for this is the 2011 Census and likely other official statistical releases). Second, how skewed the sample is for each specific wave. The less representative a specific sample is for each specific wave, the more or fewer weights need to be given to an individual observation. For example, if an individual is common in the population, but appears to be rare in a specific wave of BES participants, this may mean that an individual may be given a much bigger weight.
The within-individual variability in the weights is thus an important indicator of the quality of the underlying samples. In the end, an individual’s relative position in the population in terms of weight should be fairly static as most of his or her profile information (like age, gender, residence status etc.) do not change and most of the inputs to identify whether an individual is rare or common in the data also do not change. As a result, one should expect that an individual, whose weight was around the median of weights in wave 7, should also be around the median of weights in later waves since ultimately many of his/her individual characteristics and the characteristics of the underlying population would not have changed.
Yet, this appears to not be the case. The attached do-file and code will show a few examples. But just to illustrate: the BES participant with the ID number 1 participated in the BES panel study six-time. In wave 1, the associated weight to that individual was in the 44th percentile of the overall distribution of weights in that wave. Yet, in wave 7, he (yes we know it’s a he), was in the 82nd percentile of the weight distribution. An even starker example is the BES respondent with the ID number 4690. In wave 1, that individual was in the lower 25th percentile of the weight distribution. In wave 8, he (yes again a he), was in the 100th percentile of the weight distribution. Since many of the individual characteristics would not have changed, it highlights that the wave 8 sample appears to have been distinctly different: while in wave 1, individual 4690 had a quite low weight, he was particularly rare in wave 8, resulting in him receiving a particularly large weight. This highlights that samples are quite heterogenous in each wave despite samples of around 30,000 at each wave.
Opinion polling is very difficult. And a lot of progress has been made in making the technology cheaper and more accessible. The above analysis can be replicated with code (a simple stat do file) posted here. I do not know whether my argument has substantive academic merit and academic discourse is needed. But what can vastly facilitate this discourse is increased data transparency as most polls are conducted on even smaller samples. We know far too little about the economics and the underlying incentives that drive participation on platform-based poll providers. Innovation, such as MRP-based methods can only become much more widespread and can be developed further if access to microdata is shared with academics. Competition is good for the industry and there is a huge untapped resource: there are many very talented academics working on the BES, and public opinion data – this is a resource that the polling industry can and should tap into. Industry self-regulation provides an avenue for the sector to consider this.
This post represents the views of the author and not those of the Brexit blog, nor LSE. Image by gauge opinion, some rights reserved.
Thiemo Fetzer is an Associate Professor in the Department of Economics at the University of Warwick. He is a Visiting Fellow at the London School of Economics and is also affiliated with the Pearson Institute at the University of Chicago, the Centre for Competitive Advantage in the Global Economy (CAGE) at Warwick and the Centre for Economic Policy Research (CEPR) in London.





Thanks for an interesting analysis, discussion, with some juicy technical points to consider. I’m adding this note without looking at the data, so this is more a set of hypotheses for further discussion/investigation.
The first comment is the most important test for a voting intention question, is the comparison to the actual vote. Figure 1 shows the sample was lower than the actual result – so a remain ‘bias’ (though I believe it was within the sample error), not a leave bias. Something that the weighting in Figure 2 was making some level of correction for – the weighted result being closer to the true result than the unweighted result – so reducing the remain bias.
For the discussion on the comparison between new and old panellists, it would be important to know something about the panel replenishment methods. For large tracking surveys, it’s common to use 50% old and 50% fresh sample, matching for demographics, to reduce the impact of repeated measure effects. It’s not clear from the write up whether the panel is simply replacing – eg a young person leaves, so another young person is added – or actively refreshing across the whole sample.
If it is just replacing, then an expectation would be that younger people drop off the panel more readily than older people, and the long term repeat survey takers will therefore develop a bias to older voters – which itself is a group which tends more towards leave and would match your write up in section 5. However, the ‘fresh’ sample would not be the same demographic as the existing sample – so direct comparisons between unmatched samples would be difficult.
To test the impact of this, I’d want to understand the demographic differences between long term and short term panellists, and then to check demographically matched samples of fresh vs fresh and old vs old, to see if there is a difference between waves, and review any updates on recruitment methods wave to wave.
The comment on weighting will depend on the range of weights used. Percentile analysis is equivalent to looking at ranking of weights. To start with the basics, an unweighted sample is equivalent to weights of 1.0. An extreme weighted sample will have large weights for some respondents balanced by very small weights for others. Typically samples with weights about 2.0 or 3.0 are extreme – they effectively double, and more, the impact of an individual in the sample.
In samples of this size, which is large and likely of good quality, the weighting will be more even – so I’d expect it to be closer to 1.0 in all cases with small variations (again I haven’t seen the data). If there is a low variation in the range of weights, the ranking of weights (the median and percentiles) would then be expected to be very variable, as small variations will have larger ranking implications, and the weights depend on the achieved sample, not the individual.
For instance if men are undersampled in W1, but oversampled in W2, then a male individual would be allocated a +ve weight for W1 but a -ve weight for W2, potentially flipping their rank from top half to bottom half (the median being expected to be around 1.0).
Secondly, I don’t know what level of detail the weighting uses, but for election type studies, standard region (or possibly even constituency) is one of the factors to control, possibly also with weighting within standard region for localised results. This type of more detailed weighting creates more variation at the individual level and can aggravate the ranking effect. Percentile analysis of weights is thus not necessarily reliable as a test of potential bias with too many other factors at play.
Saul, on your first point about Remain bias, I think it’s worth considering there was almost certainly a turnout bias on the vote itself given both the “feedback mechanism on political participation” as the author noted, most polls (and media pundits) at the time had Remain already “in the bag”. Thus, the only polling question that could have been asked to achieve the 52% immediately following the poll was “How did you vote?”.