 Everyone is talking about the ethics of artificial intelligence and algorithmic decision-making. But who gets to define those ethics, and with what consequence? LSE Assistant Professor Alison Powell’s recent research, the Understanding Automated Decisions Project, looks at the explainability of algorithms and the decisions that they make, and investigated design strategies for putting explainability into practice.
Everyone is talking about the ethics of artificial intelligence and algorithmic decision-making. But who gets to define those ethics, and with what consequence? LSE Assistant Professor Alison Powell’s recent research, the Understanding Automated Decisions Project, looks at the explainability of algorithms and the decisions that they make, and investigated design strategies for putting explainability into practice.
Automated decisions – including straightforward algorithmic calculations and more complex results of machine learning and other AI techniques – are often opaque. “Any sufficiently advanced technology is indistinguishable from magic,” wrote Arthur C Clarke, science fiction writer and futurist – identifying the underlying assumption that it’s normal for end-users’ encounters with technology to be full of mystery.
This opacity, combined with the risk of bias and injustice resulting from decisions taken at the design stage, and in relation to the data used to train automated systems, means that these systems can reproduce or intensify inequalities already existing in society.
To counter this, attention is usually focused on algorithmic transparency, but is transparency in itself sufficient to bring more visibility to the values of these systems? Now, ‘explainability’ is suggested as necessary for increasing understanding of how decisions are taken by automated systems. In order to be explainable, automated decision-making needs to be transparent and accountable. In our project we defined transparency as “seeing the detail of how an automated system works,” and explainability as the “presence and quality of information about how an automated system reached a decision.” In other words, transparency is about being able to see all the information, while explainability focuses on the process behind a specific decision, in context.
For our project, we wanted to find out how combining academic and design research could result in more informed, practical outcomes that could support discussions for both academic and design communities. We also wanted to demonstrate the importance of explaining automated decisions using real use cases and contexts, in order also to see the emerging challenges in this field.
Examples
To test our ideas using concrete examples, we worked with Flock, a ‘pay-as-you go’ insurance provider for drones. Flock uses algorithms to generate insurance quotes based on data about your location, the weather and drone piloting experience. At the time we worked together, they wanted to make transparency one of their unique selling points. With our partners Projects by IF, we made several prototypes to explore how interfaces can explain different aspects of the decision-making process:
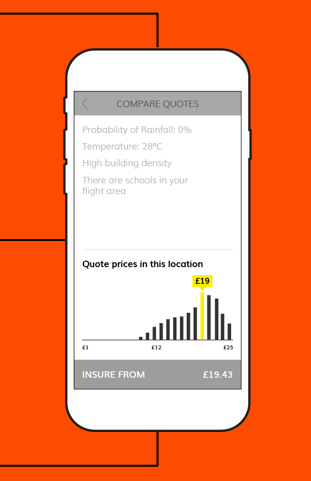 One was inspired by a paper which argues for the need to show that a clear set of rules has been applied consistently to demonstrate fairness. In this example, this prototype shows a quote calculation for a single flight, while the scale at the bottom allows you to see other quotes for the same location, and at the top you can see a breakdown of factors that led to this result. As you click on other quotes on the scale, you can see how the factors change, and how you get a different result. That shows you the rules for calculating the quotes are applied consistently, demonstrating fairness.
One was inspired by a paper which argues for the need to show that a clear set of rules has been applied consistently to demonstrate fairness. In this example, this prototype shows a quote calculation for a single flight, while the scale at the bottom allows you to see other quotes for the same location, and at the top you can see a breakdown of factors that led to this result. As you click on other quotes on the scale, you can see how the factors change, and how you get a different result. That shows you the rules for calculating the quotes are applied consistently, demonstrating fairness.
 Another prototype was inspired by a paper on counterfactual explanations: by showing you ways to reach different results, you can see how a system works. This example shows a summary of a quote including the factors that led to the result. Flock already shows how the factors affect quotes, but we went one step further, to show how your quote may have changed if the conditions had been different. This enables a better understanding of the boundaries of how a system makes decisions.
Another prototype was inspired by a paper on counterfactual explanations: by showing you ways to reach different results, you can see how a system works. This example shows a summary of a quote including the factors that led to the result. Flock already shows how the factors affect quotes, but we went one step further, to show how your quote may have changed if the conditions had been different. This enables a better understanding of the boundaries of how a system makes decisions.
Of course, for any company, a key question is how much they are willing to reveal, given that how their systems work is often a crucial part of their business model.
The limits of explanation
One of the problems with explanation is that the more complex the system, the less explainable it becomes. Federated machine learning systems, which are increasingly used to provide personalised recommendations and services on individual devices like phones, while also training global models that can automatically update millions of devices at a time are so complex as to render much explanation ineffective.
Explanation, in our exploration, included permitting people to ‘play’ with different kinds of interfaces that would illustrate different boundaries or functions of federated systems, allowing the user to roll back a model if it started to work in a way that didn’t align with expectations. However, these explanations (let’s roll back, or roll forward, or set a boundary) don’t really show how a federated system is set up: it is constantly changing, and local actions have both local consequences and statistically relevant global consequences.
Working with Google’s UX team, one of the questions we considered was whether, because there is only so much we can understand as individuals, services could be built so that multiple individuals could grant third parties the authority to act on their behalf. Such a third party wouldn’t be able to see the underlying data, but could see when, and how, a decision about that data has been made.
Explainability comes with questions and challenges, including: Who does the explaining? Who receives the explanations? In whose interests is explanation? Different actors will have different priorities. For example, in the machine learning systems that underpin the precise function of your smartphone keypad interface, a centralized model for a learning system constantly updates billions of phones at a time with a local model that learns how you like to type. My own concern includes a question about whether consumers might wish to have this process explained. There are also risks of bias and a tendency towards injustice or features that raise questions about whether this type of learning system would be good, for example, for delivering news. Yet when these systems are designed the main issues are often framed as being related to privacy and security rather than bias.
Ultimately, explanation may not be sufficient for justice. Through the efforts at exploring interface and public engagement as strategies to identify the possibilities of explanation, I was struck by the public’s interest in the nuances of explanation, and also the fact that trust is contextual. We are working in a political and social context where truth, connection to facts, and legitimacy are under threat. To avoid enabling an expansion of the mistrust of explanation, it should be used judiciously, and that designers and developers should think very carefully about the purpose of explanation, whether explanation is appropriate, or whether the public good is better served by not employing systems that are explanation-resistant in certain contexts.
This article represents the views of the author, and not the position of the Media@LSE blog, nor of the London School of Economics and Political Science.


