
The assumptions behind various election forecasting models lead to different central predictions for the outcome on May 7th. In this post, Chris Hanretty, one of the team at electionforecast.co.uk, evaluates two assumptions that differ across three of the main academic forecasting projects for the election in 2015.
See electionforecast.co.uk‘s recent “Predicting the polls” piece here.
As the several and varied posts on this blog attest, there are many different academics who are attempting to forecast the outcome of the 2015 general election. These forecasts use different sources of information, but one group of models relies primarily on information from opinion polls. These models generally have to perform two tasks:
- to generate a forecast of the national vote share won by each (relevant) party
- to translate this national vote into seat tallies (or, alternately, to take seat nowcasts and bring them in line with the national forecasts)
Different forecasting models can approach each of these two tasks differently. As such, differences between forecasts may be the result of a different national vote forecast, or a different mapping between votes and seats, or both. However, differences which result from different national vote forecasts are self-effacing. That is, as we get closer to the election, the weights these different models place on polls will increase, and the role played by assumptions about the evolution of public opinion will decrease. It’s therefore helpful to work out whether differences between different forecasts will be self-effacing in this sense.
Here are the vote forecasts for three different forecasting models, along with their associated 95% credible intervals. The dates of the forecasts are as follows:
- ElectionsEtc.com: 10th April.
- Polling Observatory: 1st April.
- ElectionForecast.co.uk: 9th April.
Note that for the SNP forecast for ElectionsEtc I’ve multiplied the Scotland-only vote share estimate by Scotland’s share of turnout in 2010 to produce a UK estimate.
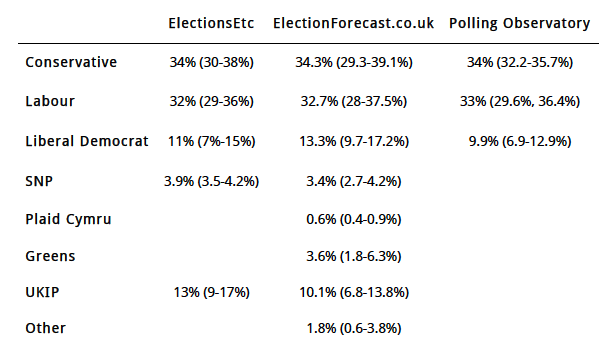
These estimates of national vote share produce the following seat forecasts:
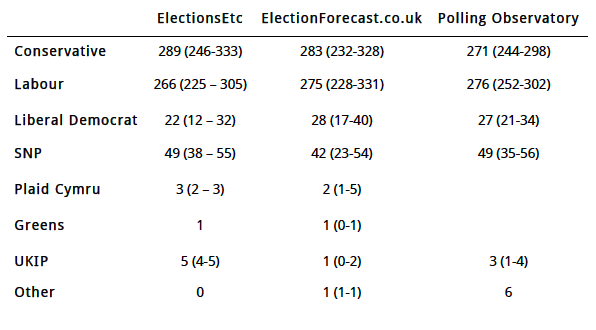
We can assess how different each forecast is from each other by calculating the absolute differences in seats across all parties. To do so, I’ll assume that the 6 seats Polling Observatory has as “Other” are 3 Plaid Cymru seats, 1 Green seat, and 2 other “Other” seats.
The differences are therefore
- between ElectionsEtc and ElectionForecast.co.uk: difference of 34 seats
- between ElectionsEtc and Polling Observatory: difference of 36 seats
- between ElectionForecast.co.uk and Polling Observatory: difference of 24 seats
These differences are thus relatively minor, even though the central forecasts have dramatically different political consequences.
How much of these differences is attributable to different national vote forecasts? Here, I’ve simulated some national vote shares on the basis of these different forecasts, and asked the electionforecast.co.uk model to reconcile our seat figures with these national vote shares. Where a forecast offers no national vote share for a set of parties, I’ve assumed that the remainder (e.g., 100 – (Con + Lab + LDem) in the case of the Polling Report forecast) is distributed across parties in the same ratio as it is in the electionforecast.co.uk forecast.
The table below shows what happens if we ask our model to imitate the vote share projections of ElectionsEtc and Polling Observatory.
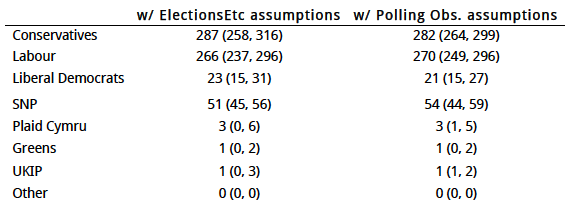
How different are the forecasts now?
- between ElectionsEtc assumptions and ElectionForecast.co.uk assumptions: difference of 29 seats, compared to 34 seats before
- between ElectionForecast.co.uk assumptions and Polling Observatory assumptions: difference of 27 seats, compared to 24 seats before.
This means that when we look at the difference between ElectionsEtc and ElectionForecast.co.uk seat forecasts, (34 – 29)/34 = 15% of the difference is due to different assumptions about the national vote. The remainder of the difference is due to a different mapping of votes to seats.
Conversely, when we look at the difference between the Polling Observatory and ElectionForecast.co.uk, the different assumptions about the national vote cut in different directions. When we adopt their assumptions, we actually disagree with them more!
Thus, some of the differences we’ve seen across forecasting teams will persist until the day of the election. These differences will carry across to our assessment of the accuracy of each forecast, assessed against the actual outcome. However, given that the differences between forecasts are slight (and smaller than the “expected prediction error”, the error we would expect given that forecasts are probabilistic), then the most accurate forecasting team will have to be lucky as well as skilled.
Note: Figures are accurate as of April 10th, 2015.
Chris Hanretty is a Reader in Politics at the University of East Anglia.




Interesting. I’m looking forward to seeing who produces the most realistic final seat prediction on the day – and also in retrospect, using the actual General Election vote percentages.